

















1. Go to the Google Cloud Console homepage via the link below.
https://console.cloud.google.com/
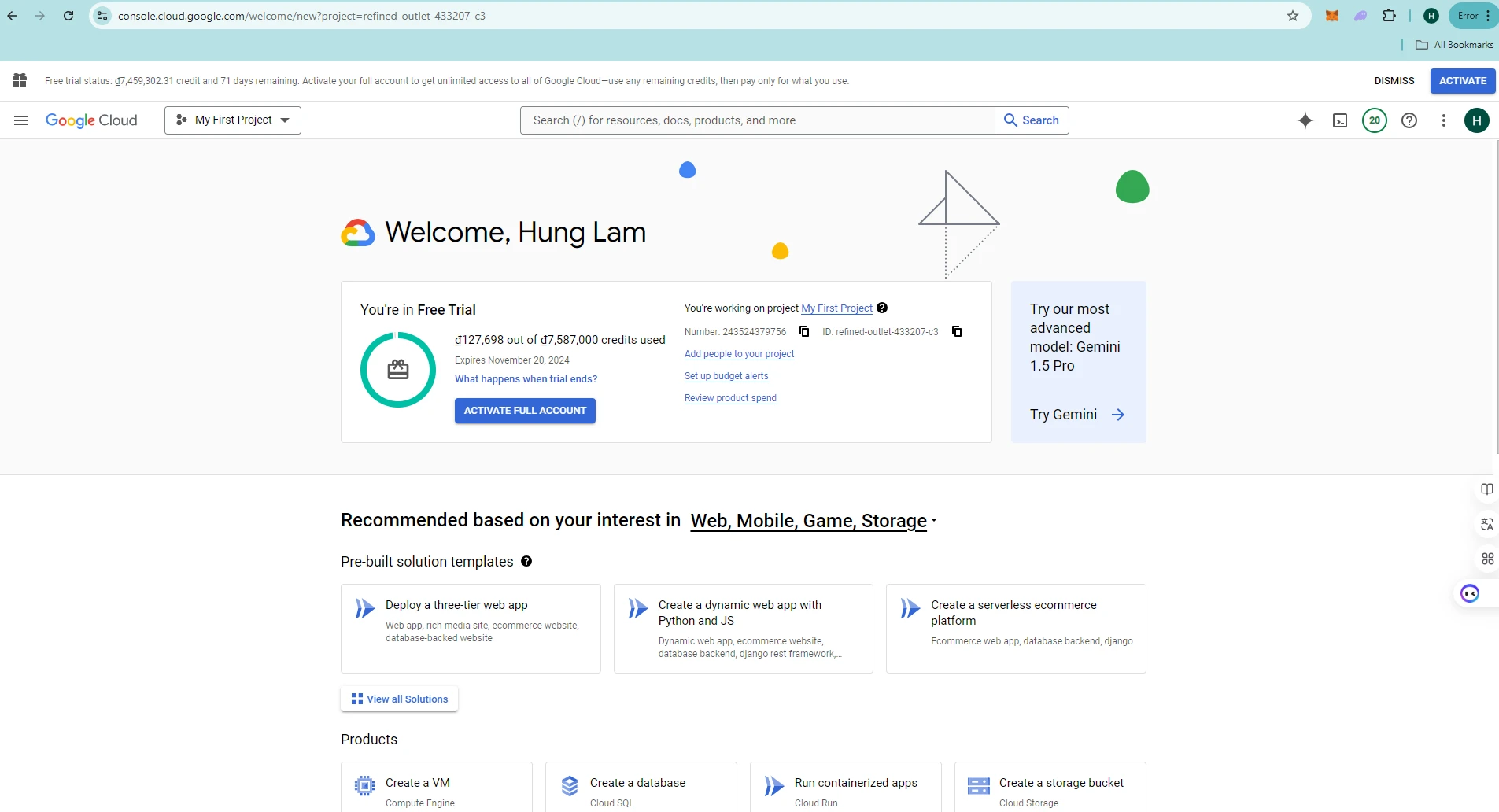
2. Create a new project for you application
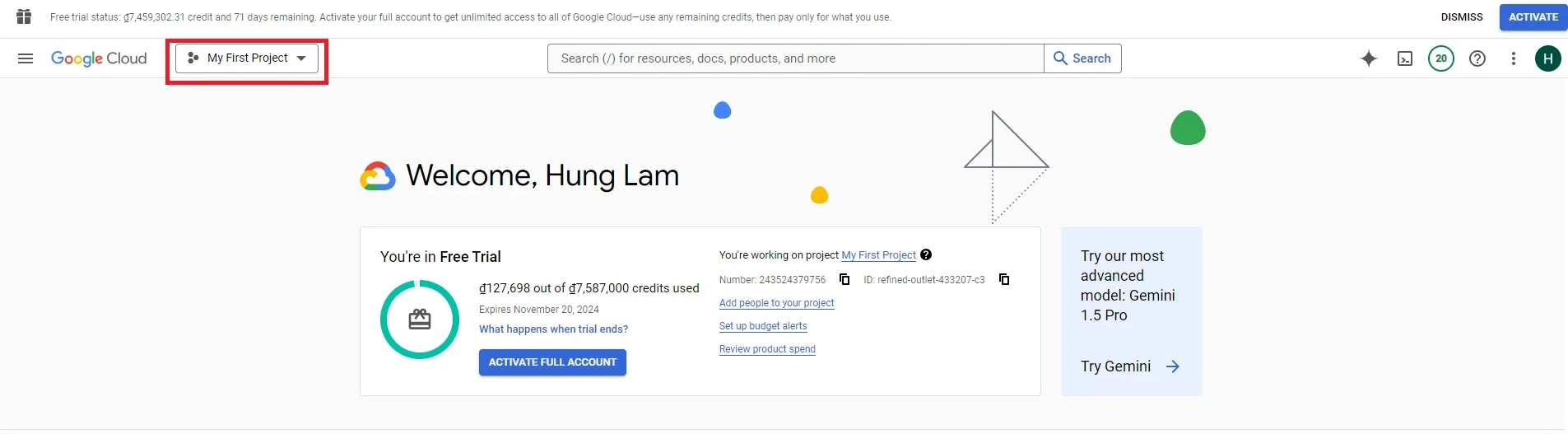
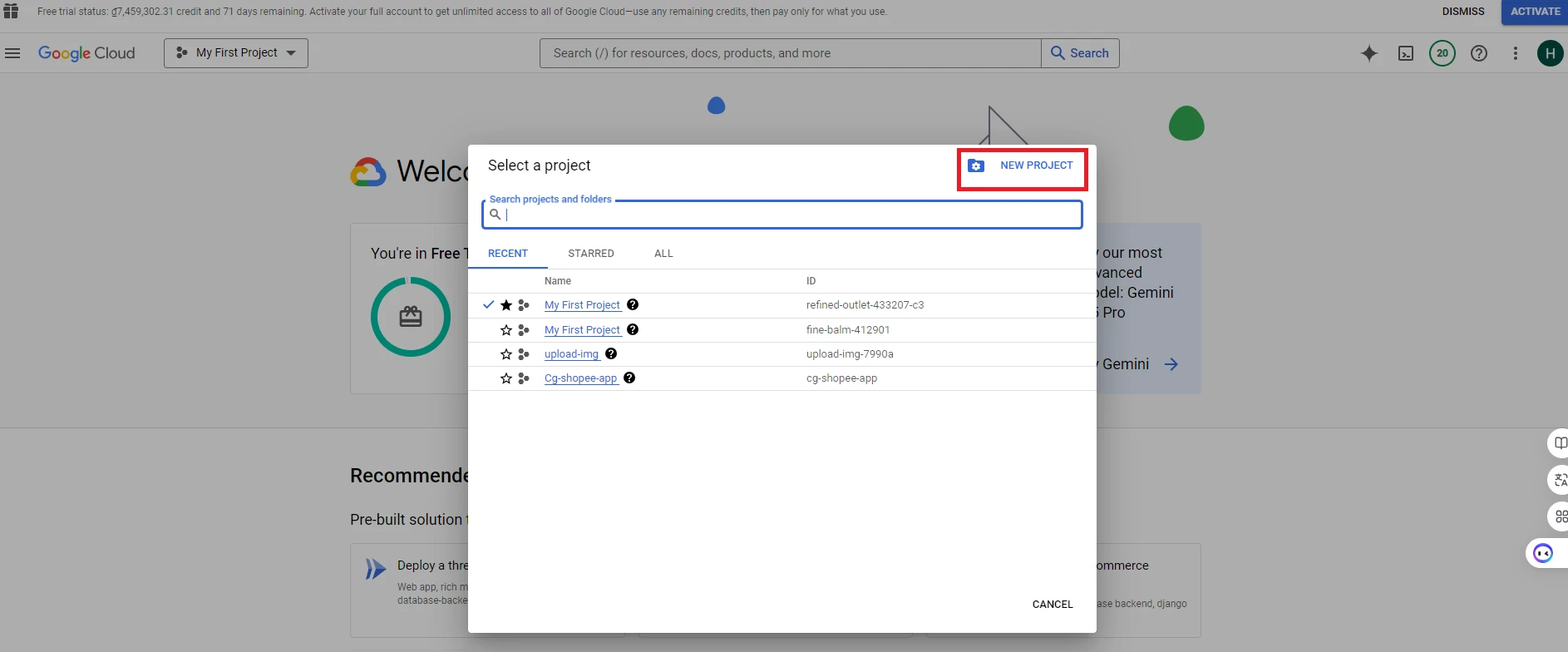
3. After creating and selecting a project, go to the search bar and type ‘BigQuery’
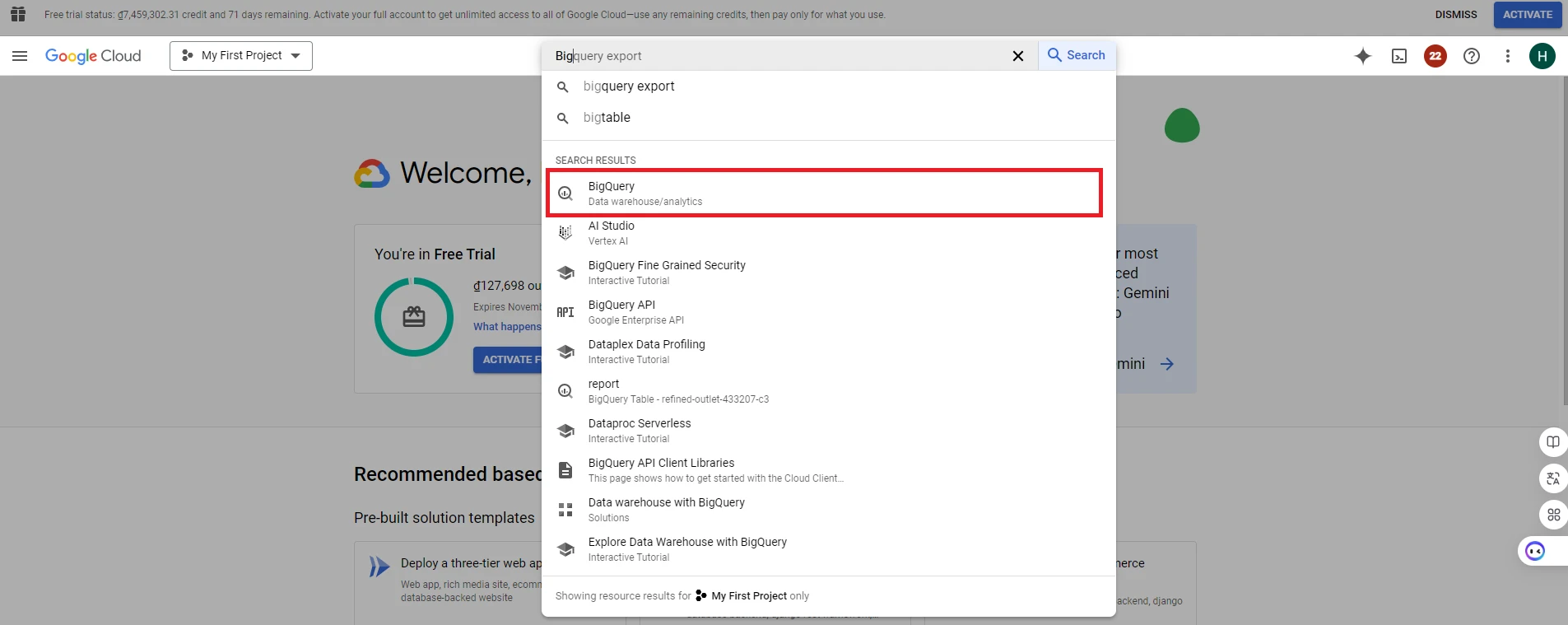
4. After accessing the BigQuery page, click ‘Enable’ to activate the Google BigQuery API. (When you want to use a specific feature of Google Cloud, you need to enable its API so that your application can connect to that feature’s API)
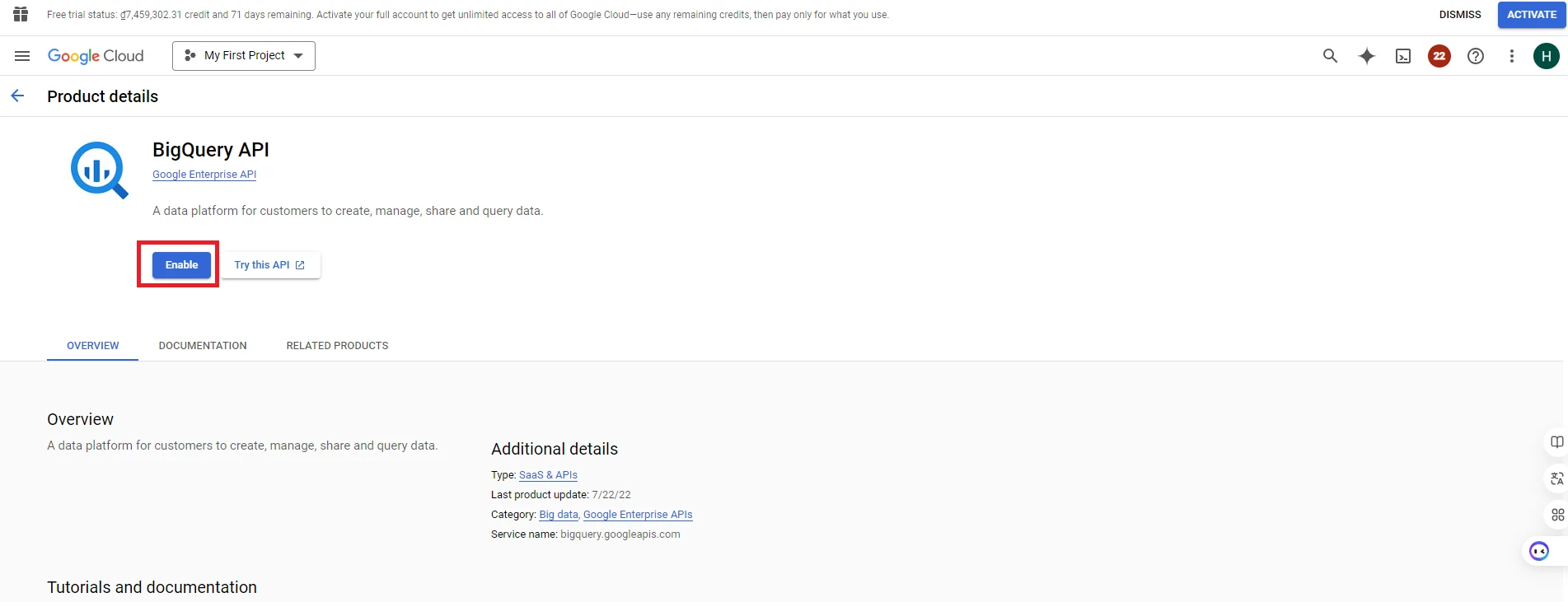
5. After enabling BigQuery API, next you need to grant permissions to work with BigQuery for the account you will use for the application. Click Navigation menu => Select ‘IAM & Admin’ section => Select ‘IAM’ (Identity and Access Management)
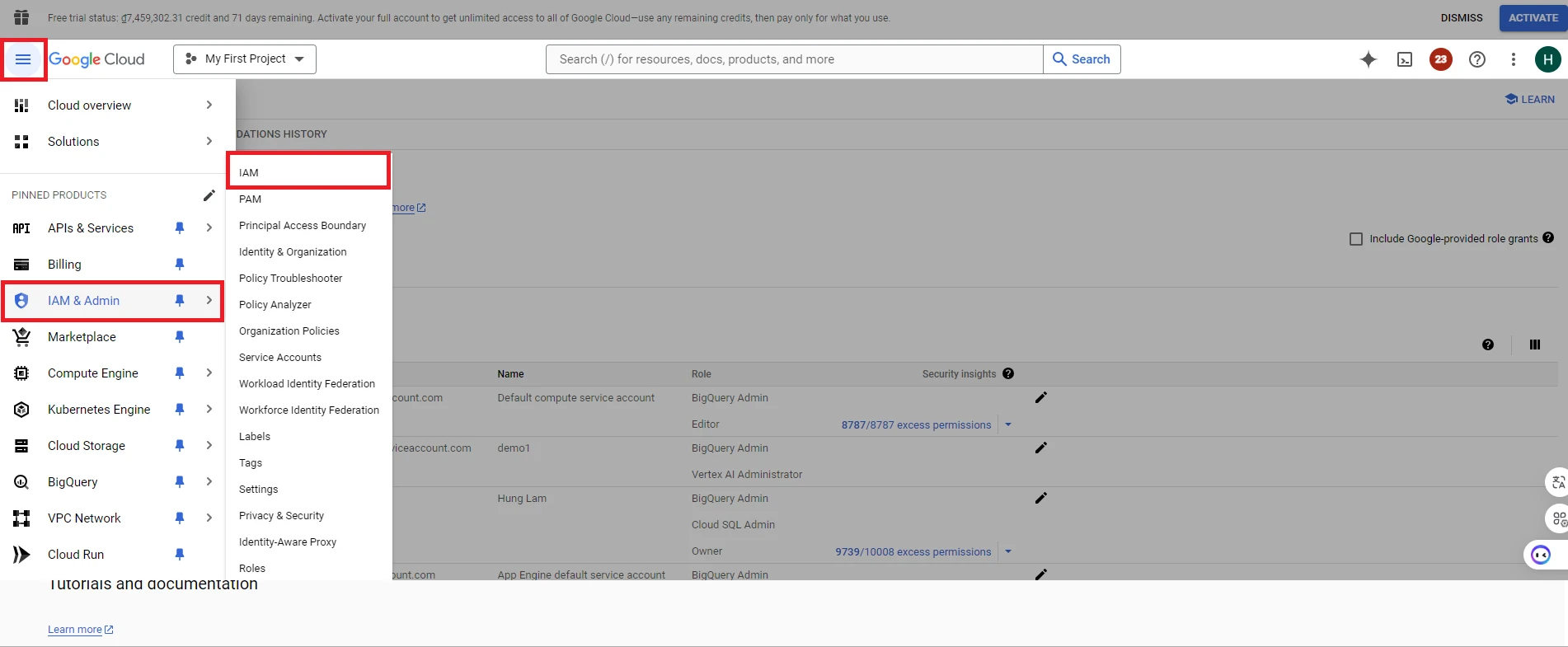
6. Select the account you want to edit to grant permissions for working with the BigQuery API
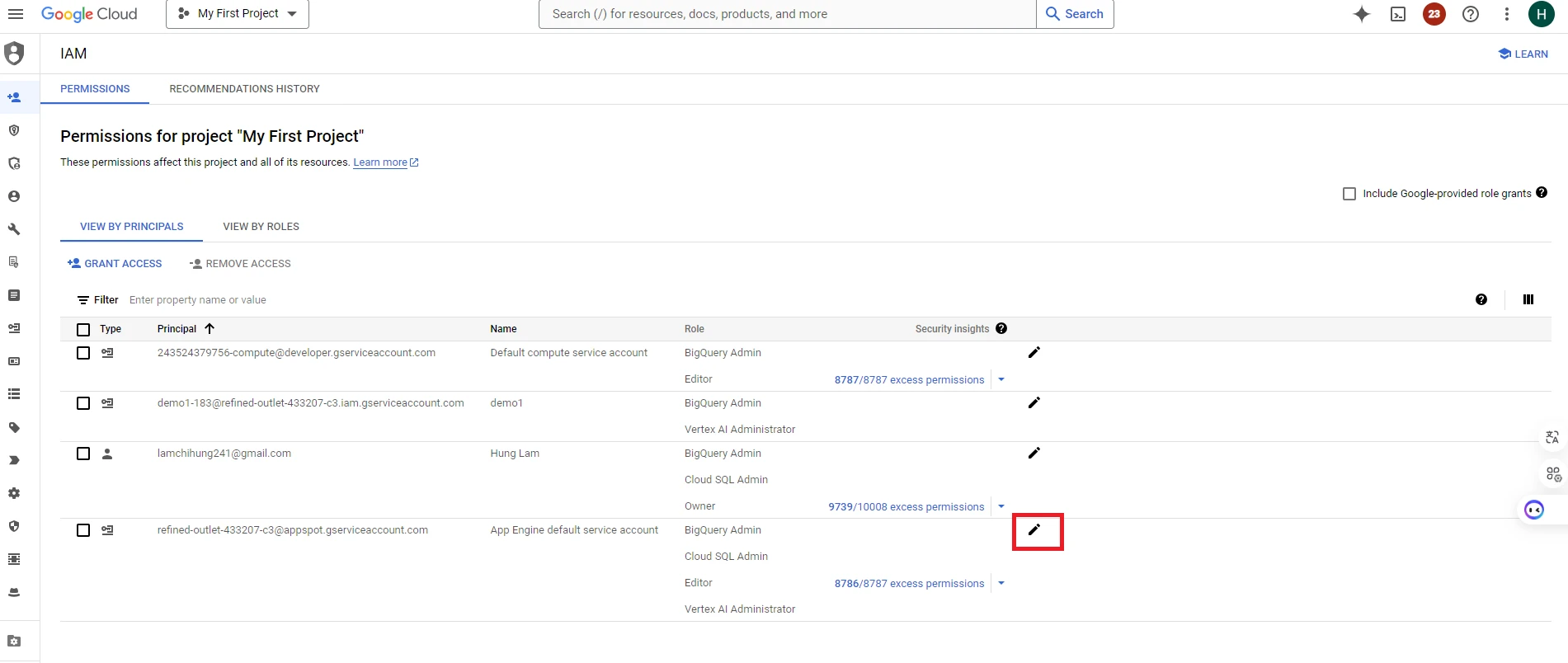
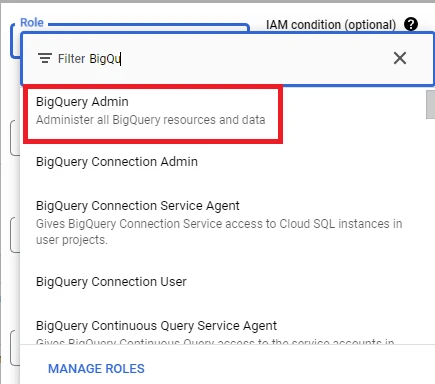
7. Then click ‘ADD ANOTHER ROLE’ => Click Role BigQuery Admin for your account
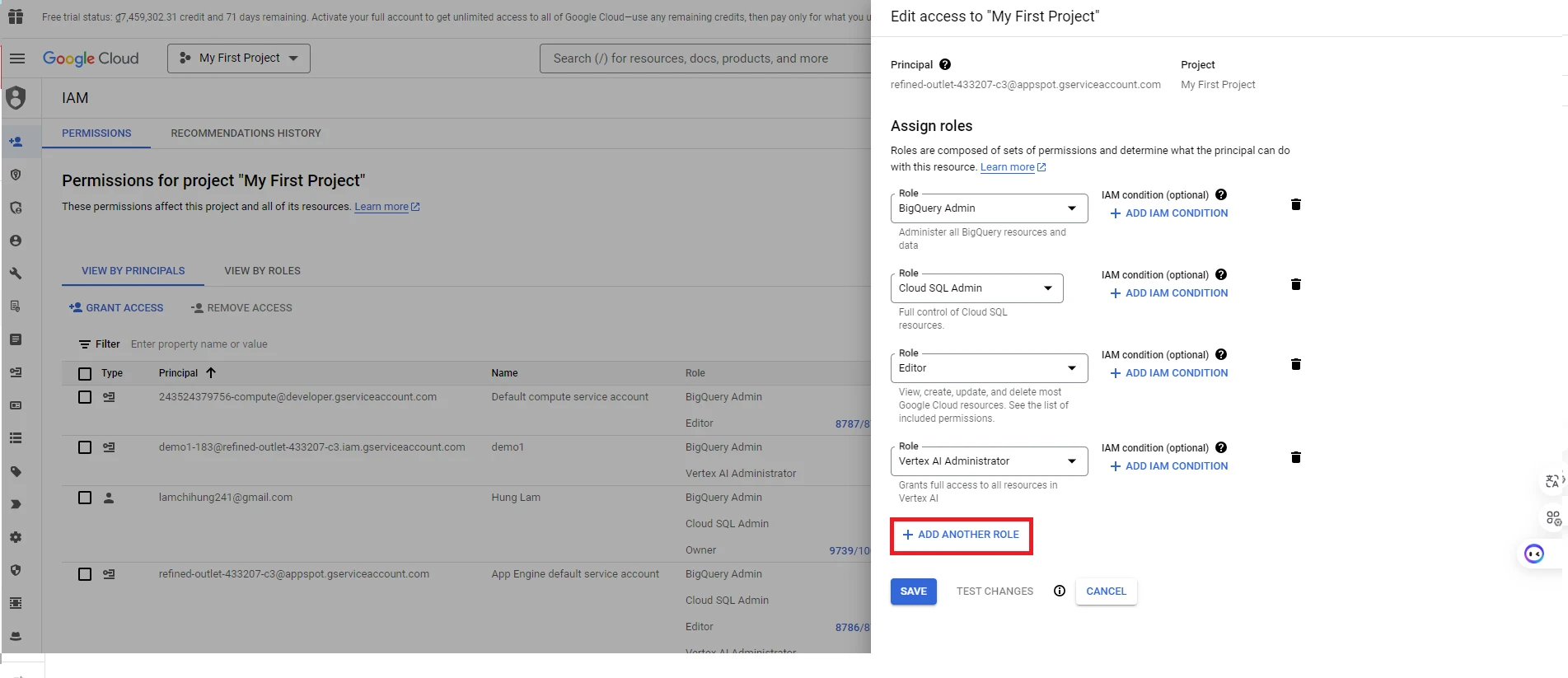
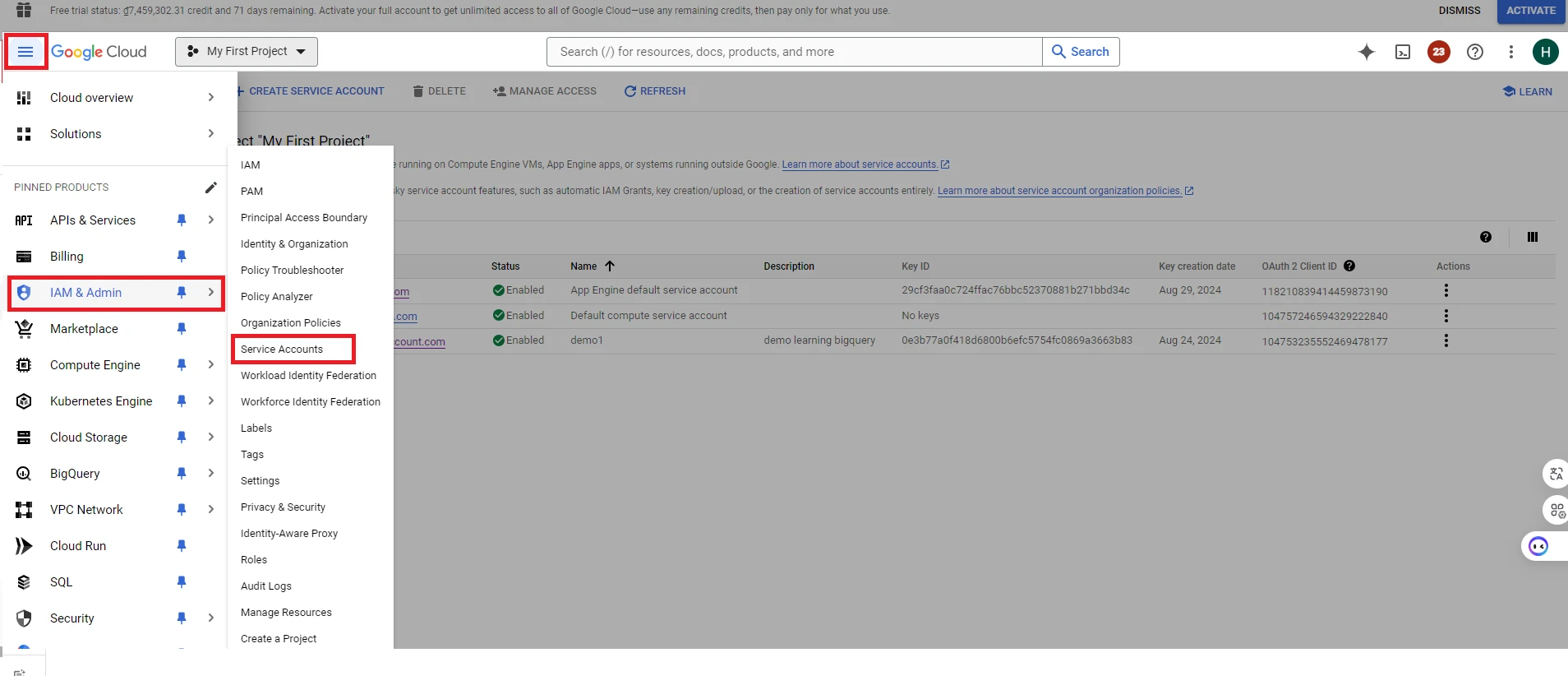
8. Next, we need to download the keys for the account to create Google Credentials in the application. Click Navigation menu => Select ‘IAM & Admin’ section => Select ‘Service Accounts’
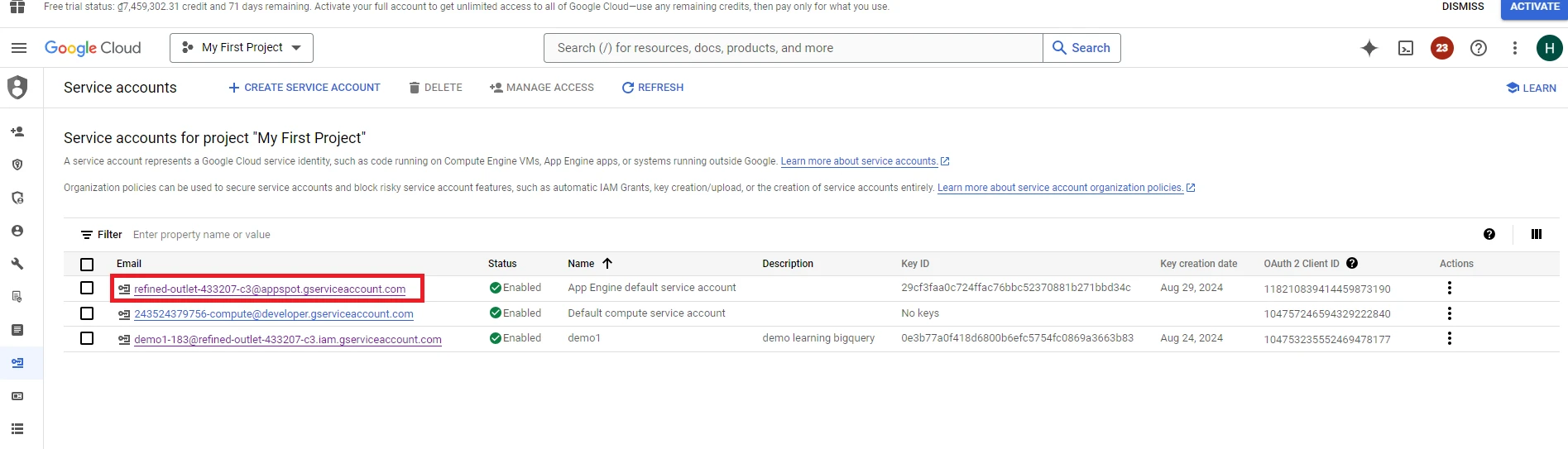
9. Select the account for which you granted the ‘BigQuery Admin’ role in the previous step
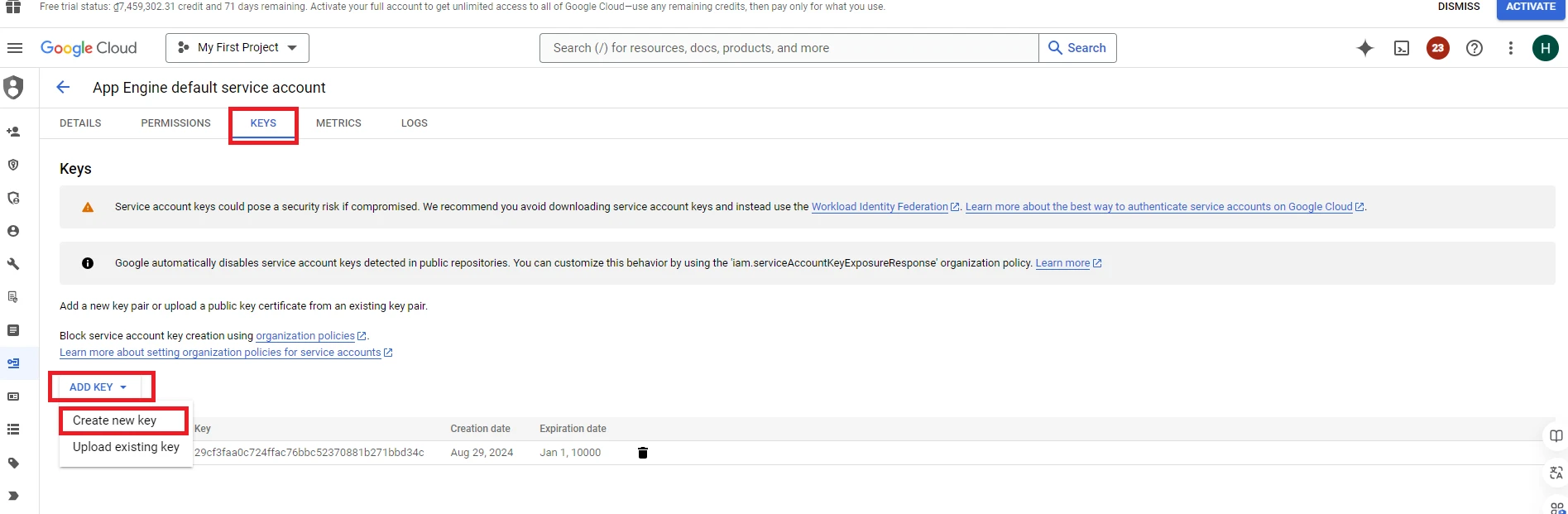
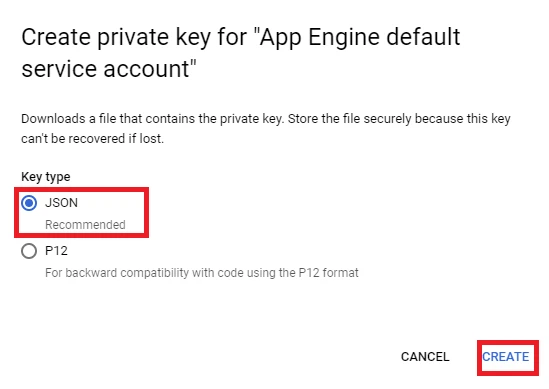
10. Click ‘KEYS’ => Select ‘ADD KEY’ => Select ‘Create new key’ => Choose JSON key type => Select ‘Create’. At this point, Google will automatically download the JSON key to your computer

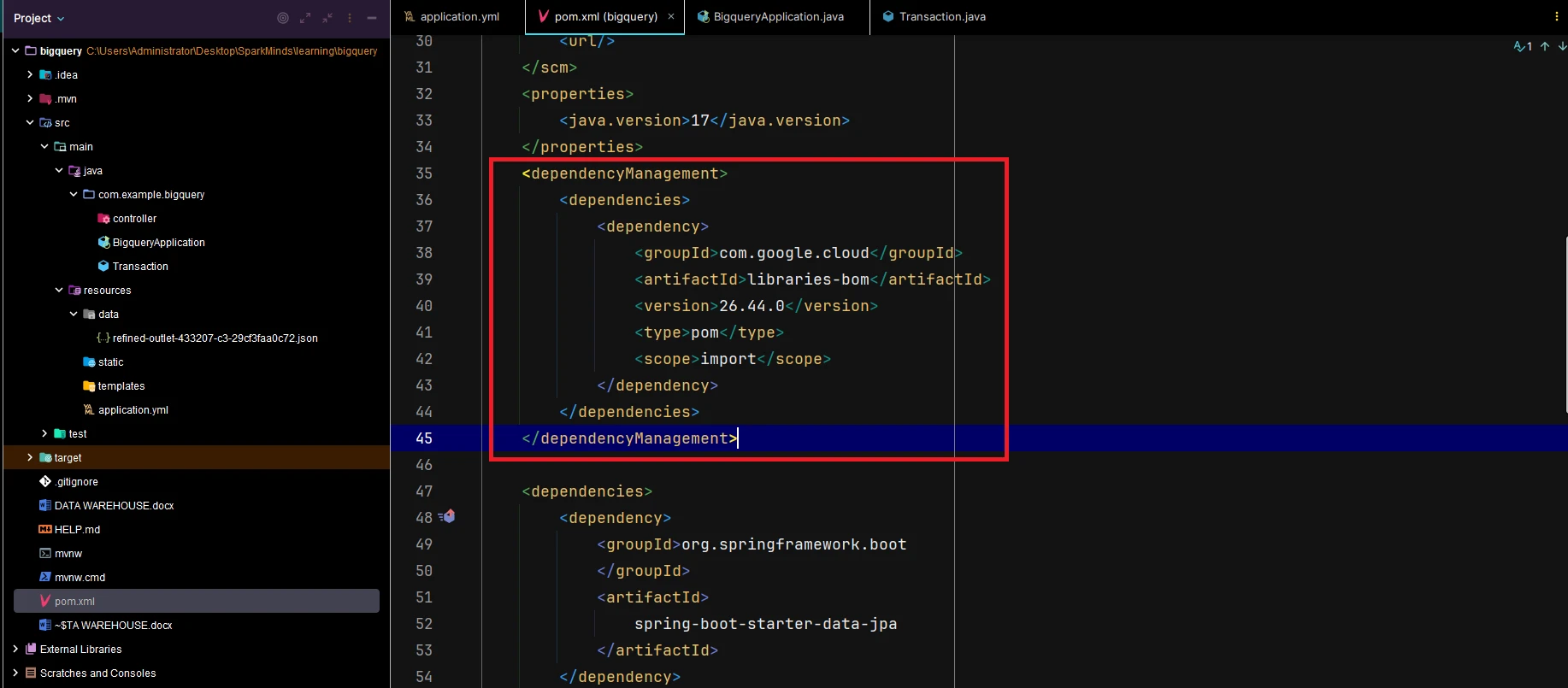
1. Open the pom.xml file and add dependencies from Google BigQuery
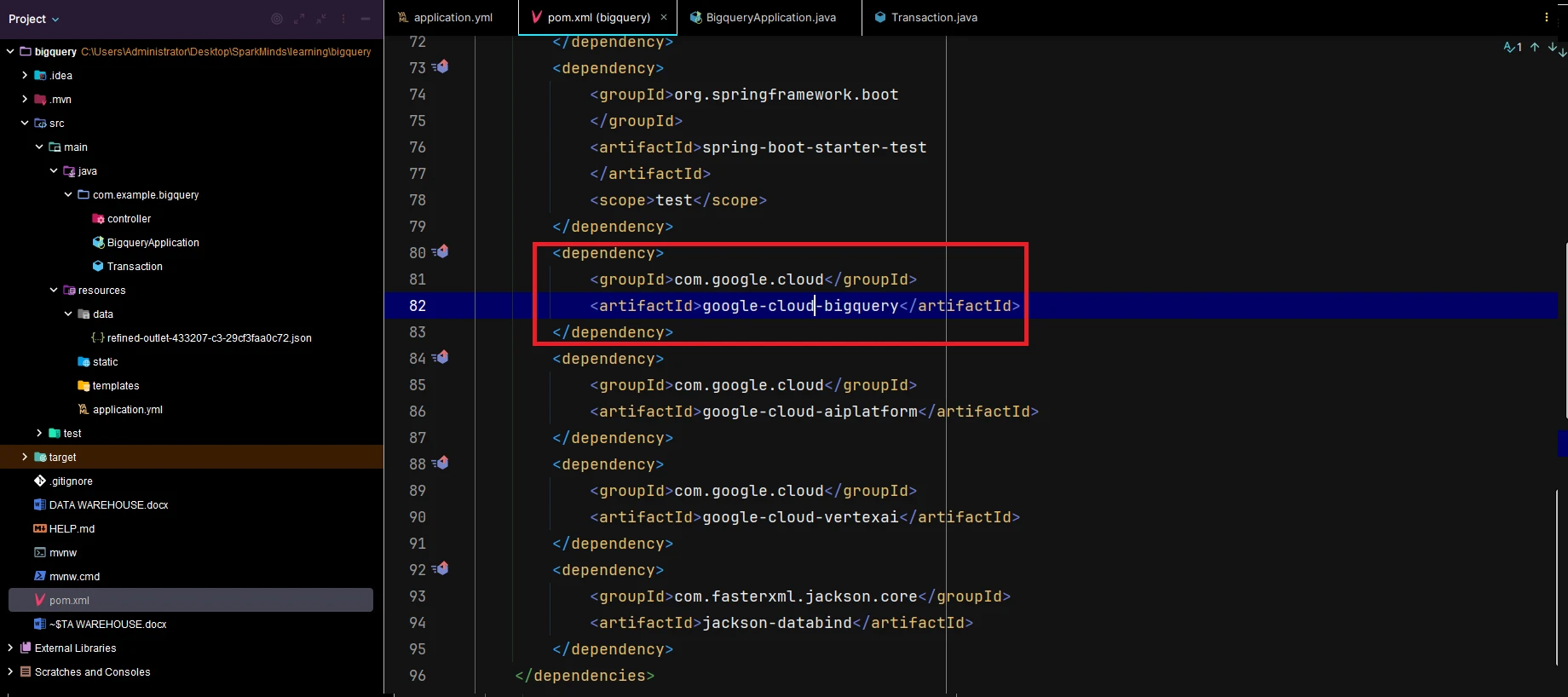
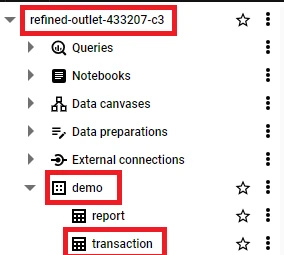
2. Save the details of the project, dataset, and table that need to be interacted with in BigQuery
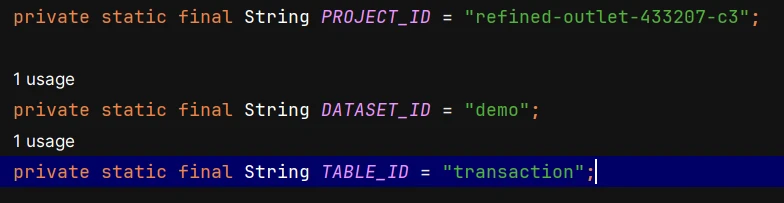
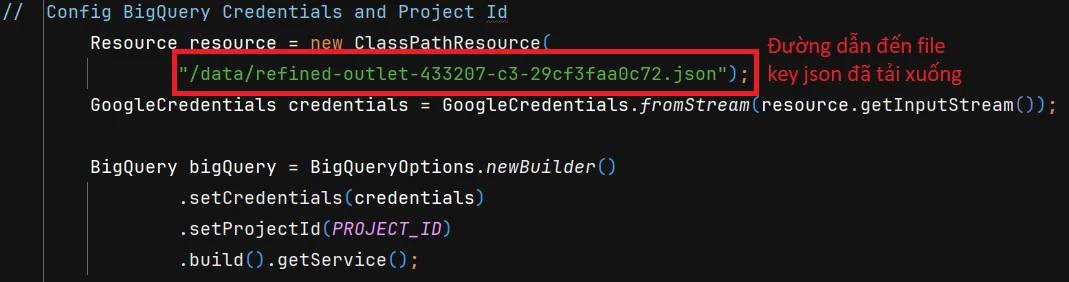
3. Configure Google Credential and Project
This is the path to the downloaded JSON key file.
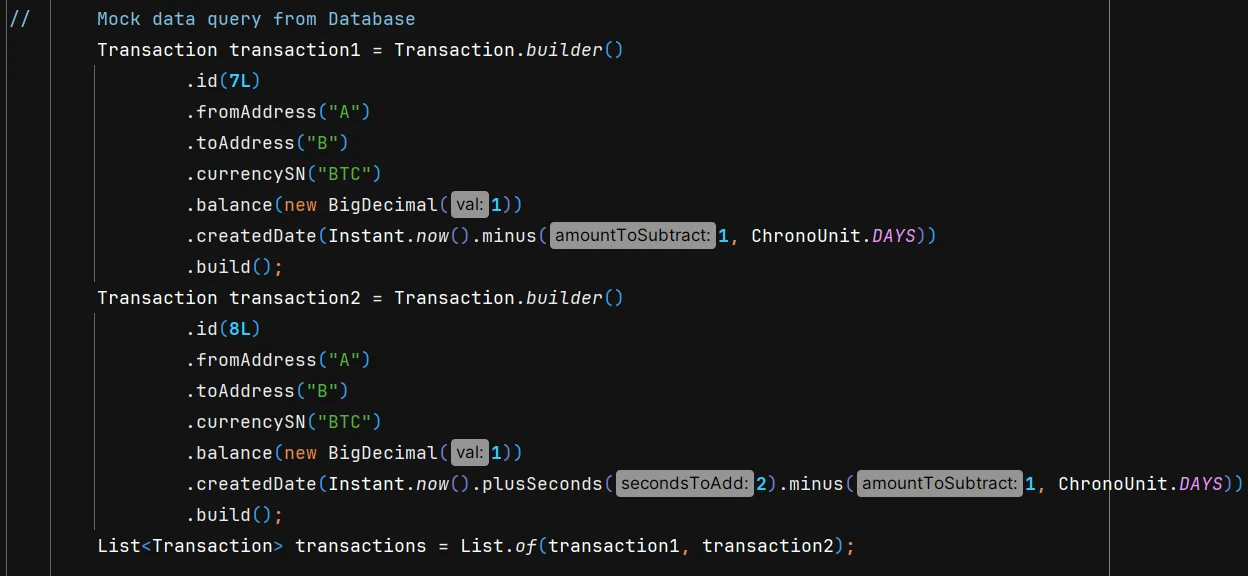
4. Query data from the Database (This guide will only mock the data)
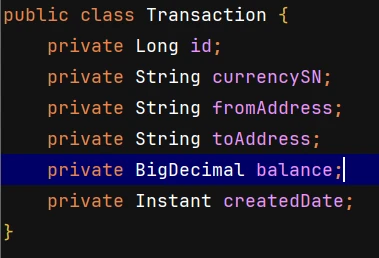
5. Convert the data into Google BigQuery’s RowToInsert object
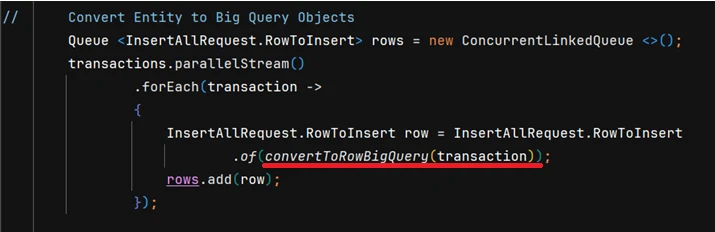
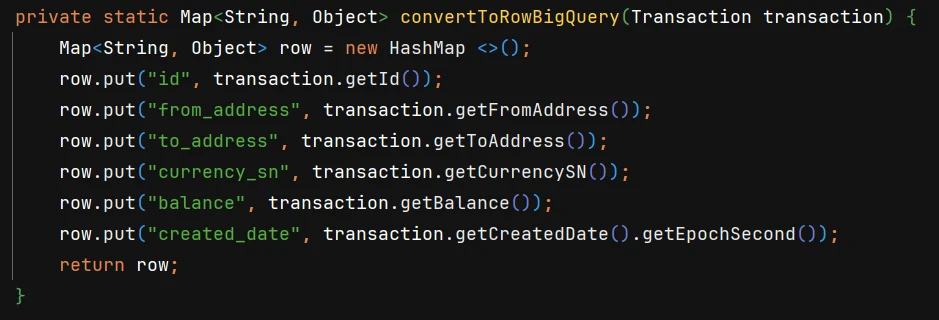
6. Insert the data into BigQuery
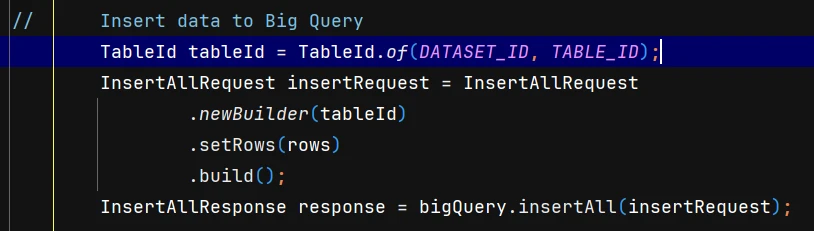

You have now completed the function of transferring data from the Database to the Data Warehouse using a Java Application. Next, you will implement the functionality to query data from BigQuery
7. Create a query

8. Create a BigQuery job from the query and execute it
9. Check for any errors and display the results received.
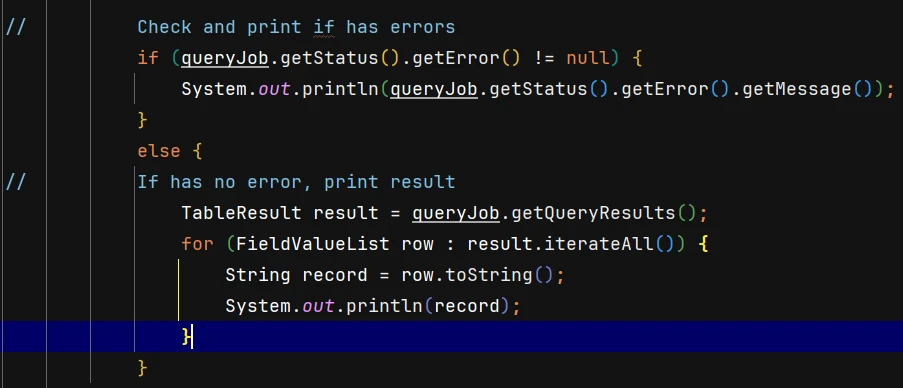

Example Result:
[
FieldValue{attribute=PRIMITIVE, value=1},
FieldValue{attribute=PRIMITIVE, value=BTC},
FieldValue{attribute=PRIMITIVE, value=A},
FieldValue{attribute=PRIMITIVE, value=B},
FieldValue{attribute=PRIMITIVE, value=1},
FieldValue{attribute=PRIMITIVE, value=1725718844.0}
]
You’ve now finished setting up the process for querying data from BigQuery using a Java Application. Next, we’ll walk you through how to transfer data from the Database to BigQuery and generate regular reports—without needing a Java Application.
Datastream for BigQuery is a Google Cloud service that allows you to replicate data from relational databases, such as MySQL, PostgreSQL, Oracle, and others, into BigQuery
![]()
1. Go to Google cloud console, Search for the Datastream and enable API features
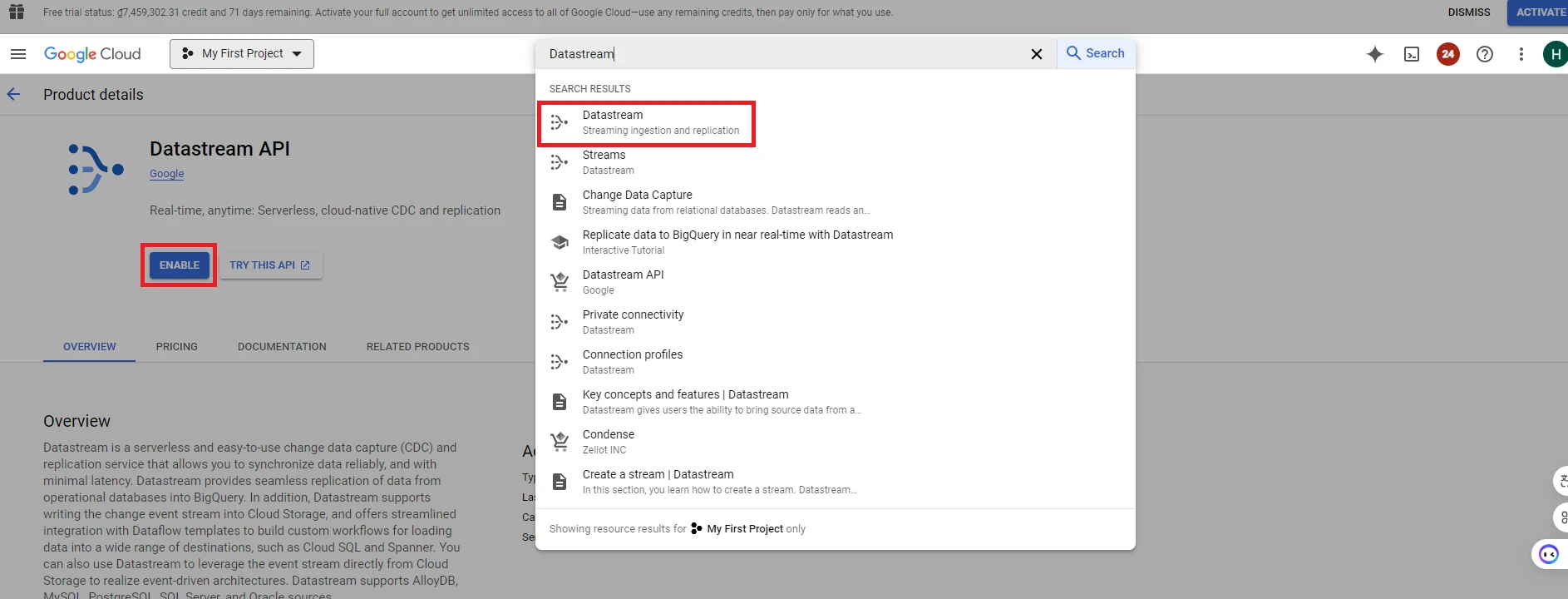
2. Create Stream
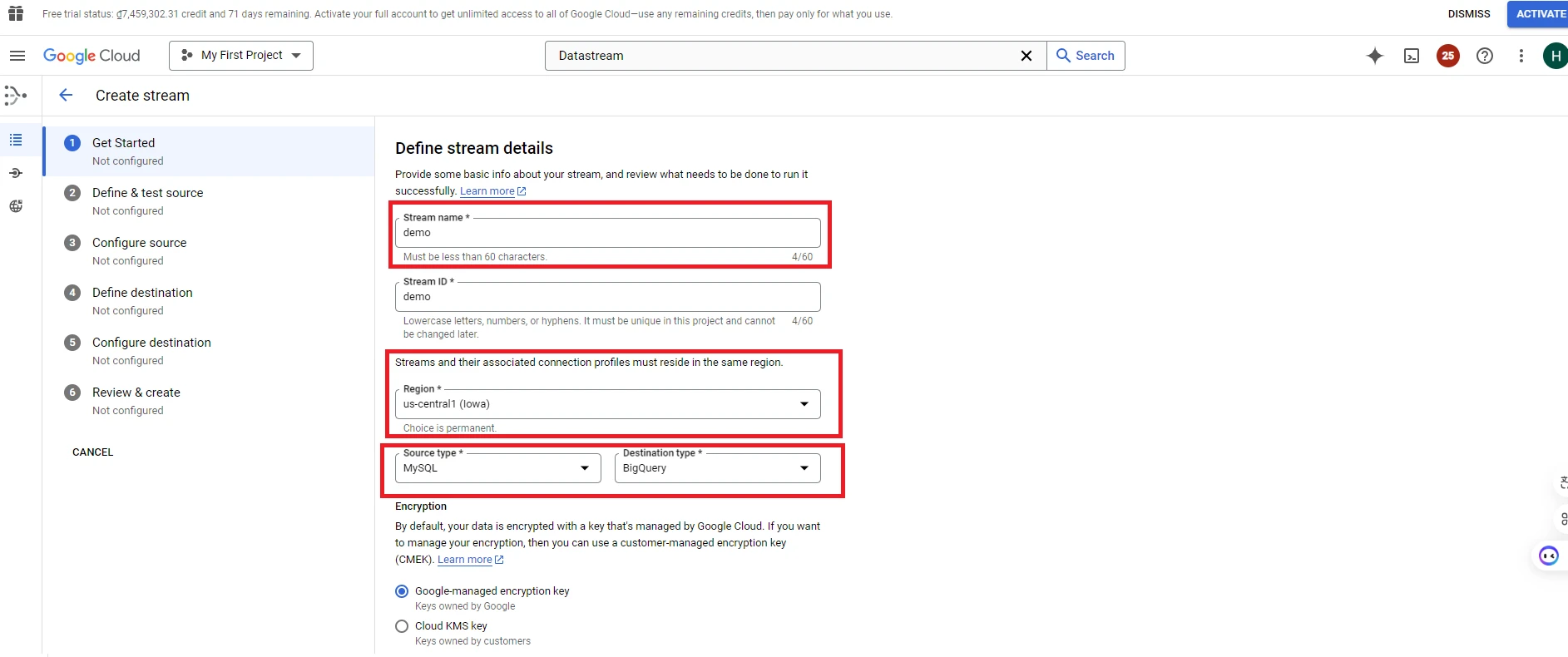
3. Fill the information in the ‘Create stream’ table:
– Stream name: Set a name for your stream
– Region: Select a region
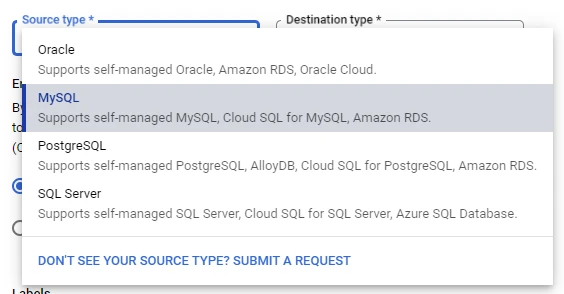
– Source Type: Choose one of these source types: Oracle, MySQL, Postgre, SQL Server
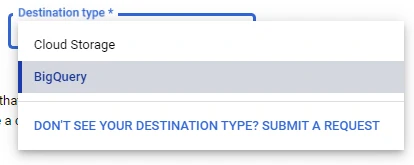
– Destination Type: Choose one of these destination types: Cloud storage, BigQuery
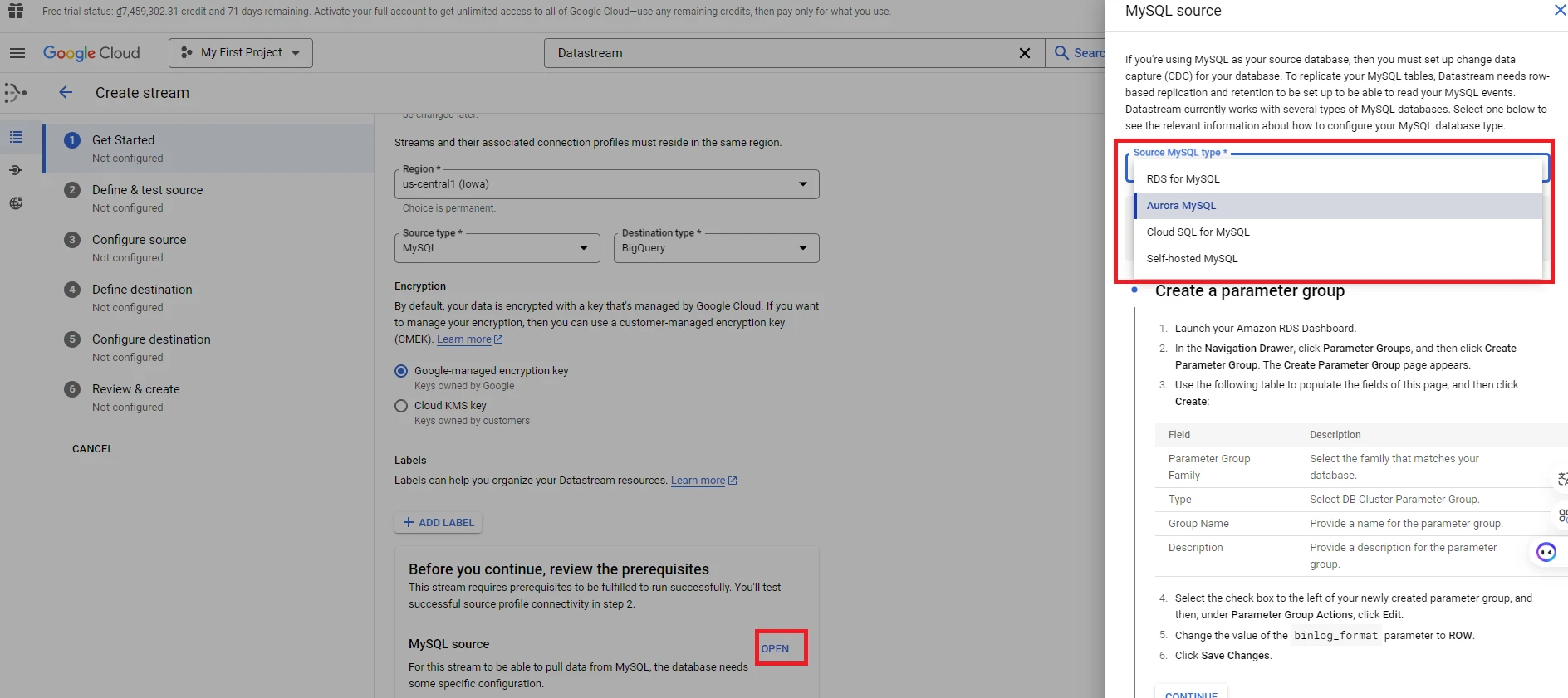
4. For Datastream to pull data from the Database, the Database needs a few configurations. Depending on the type of Database you are using, follow the relevant configuration instructions. (In this guide, we will use Cloud SQL for MySQL).
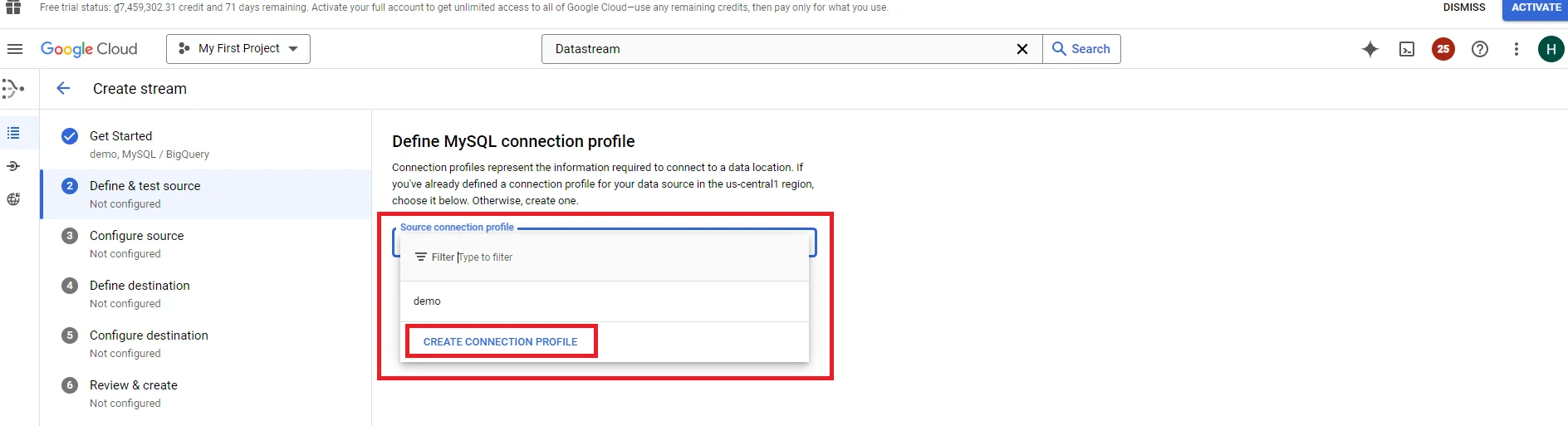
5. Click ‘Next’ to go to the next form. In the following form, you’ll need to enter the information to create a connection profile
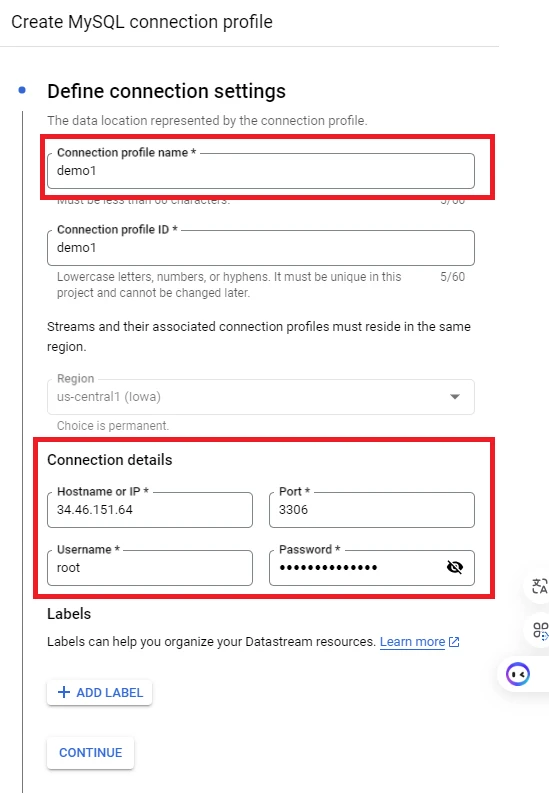
6. Fill the information in the‘Create MySQL connection profile’ table:
– Connection profile name: The name of connection profile
– Hostname or IP: Hostname or IP address of your database.
– Port: Port database you’re using
– Username: The login name for the database account
– Password: The password for the account
7. Next, you can configure the security settings for your stream. In this guide, we will use the default settings. The IP addresses listed below will be accessing your database, so make sure to configure your database to allow connections from these IPs.
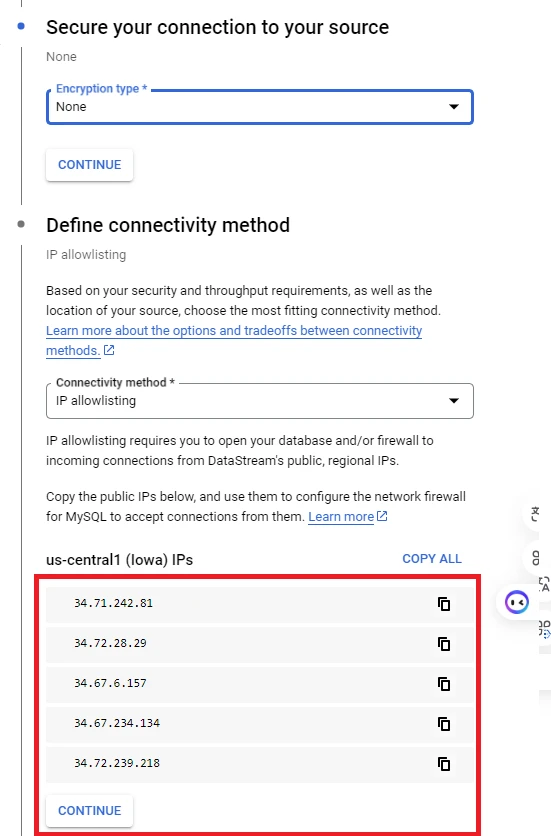
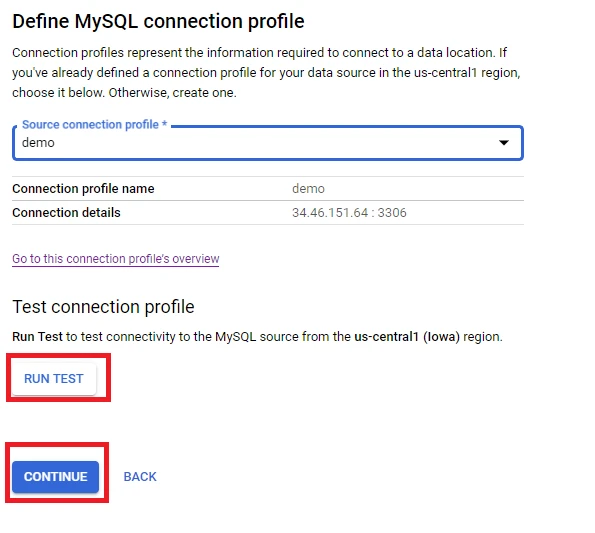
8. Click ‘Run test’ and then click ‘Continue’
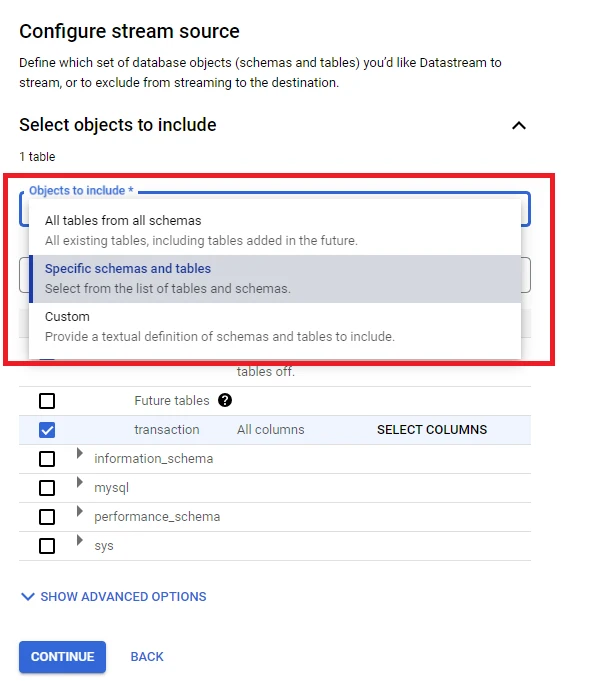
9. Fill the information in the ‘Configure stream source’ table:
– Objects to include:
+ All tables from all schemas: Stream all tables and all schemas in the Database
+ Specific schemas and tables: Select tables and schemas you want to stream
+ Custom: Similar to specific schemas and tables, but using text instead of checkboxes to select
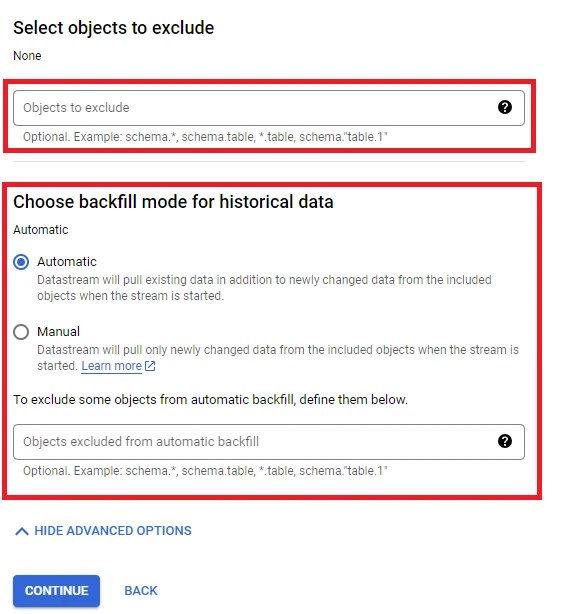
10. Select ‘SHOW ADVANCED OPTIONS’, enter the information in this table:
– Objects to exclude: Choose the data you do not want to stream: schema, table, or column.
– Choose backfill mode for historical data: Select the mode for data that existed before using the stream:
+ Automatic: Stream all existing records in the Database and any records created after the stream is started
+ Manual: Only stream records created after starting the stream
11. Click CONTINUE, fill the information in the ‘CREATE CONNECTION PROFILE’ table
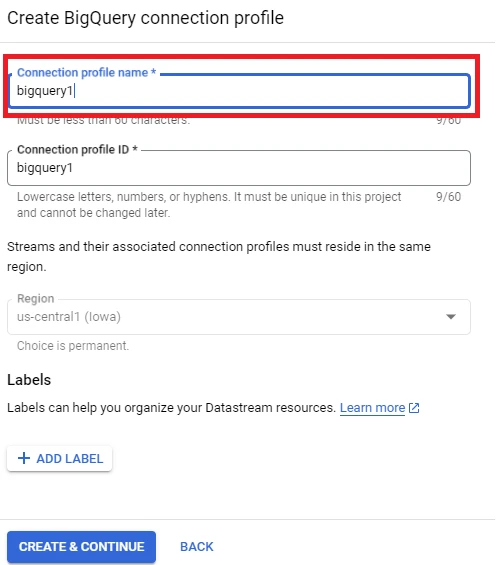
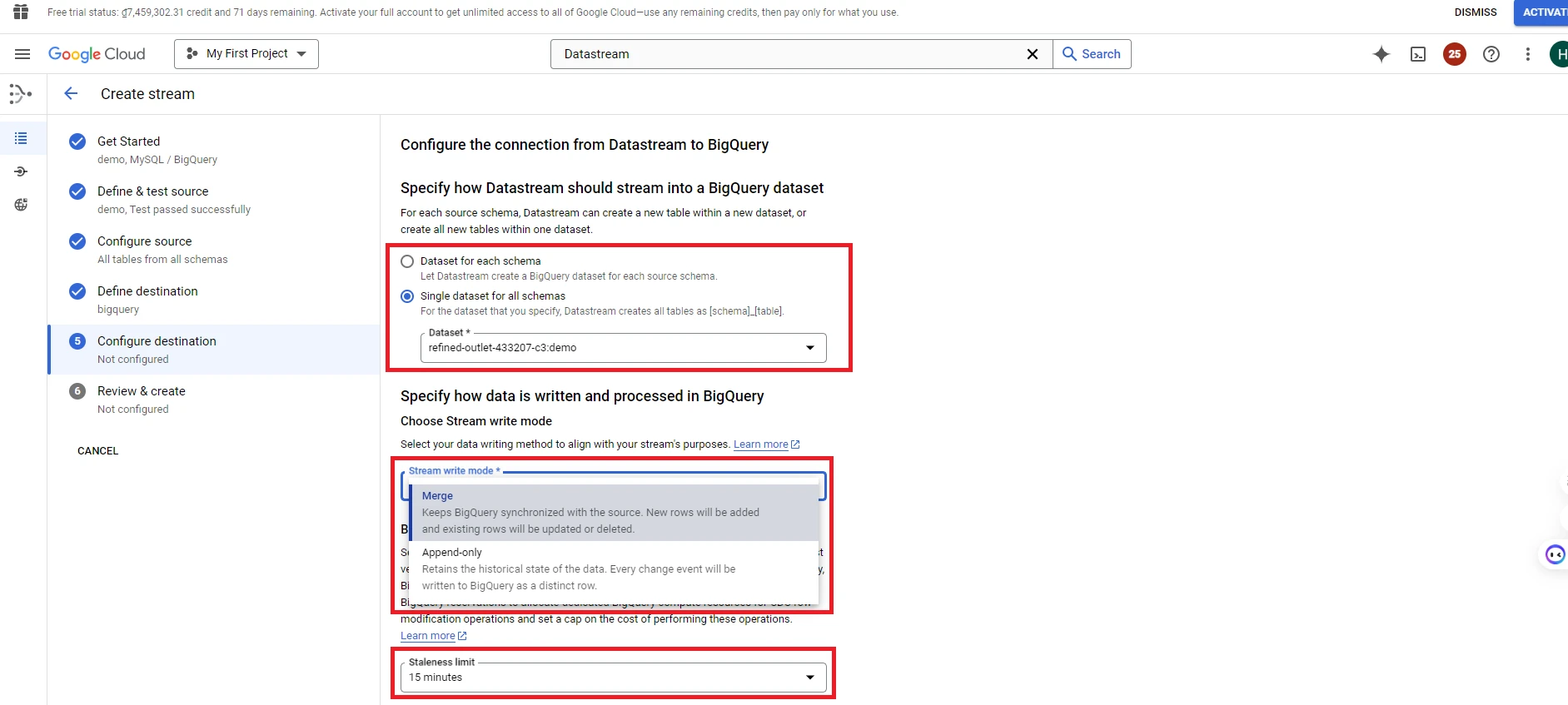
12. Select CONTINUE, enter the information in the ‘Configure the connection from Datastream to BigQuery’ table:
– Specify how Datastream should stream into a BigQuery dataset:
+ Dataset for each schema: Each schema will stream into its own dataset
+ Single dataset for all schemas: All schemas will stream into a single dataset
– Stream write mode:
+ Merge: Synchronize records with the database. We can add, update, or delete records according to the database
+ Append-only: Each event (insert, update, delete) in the database will be recorded in BigQuery
– Stateleness limit: Scheduled update time for data from the database to BigQuery
13. Review the information, select run validation and create stream
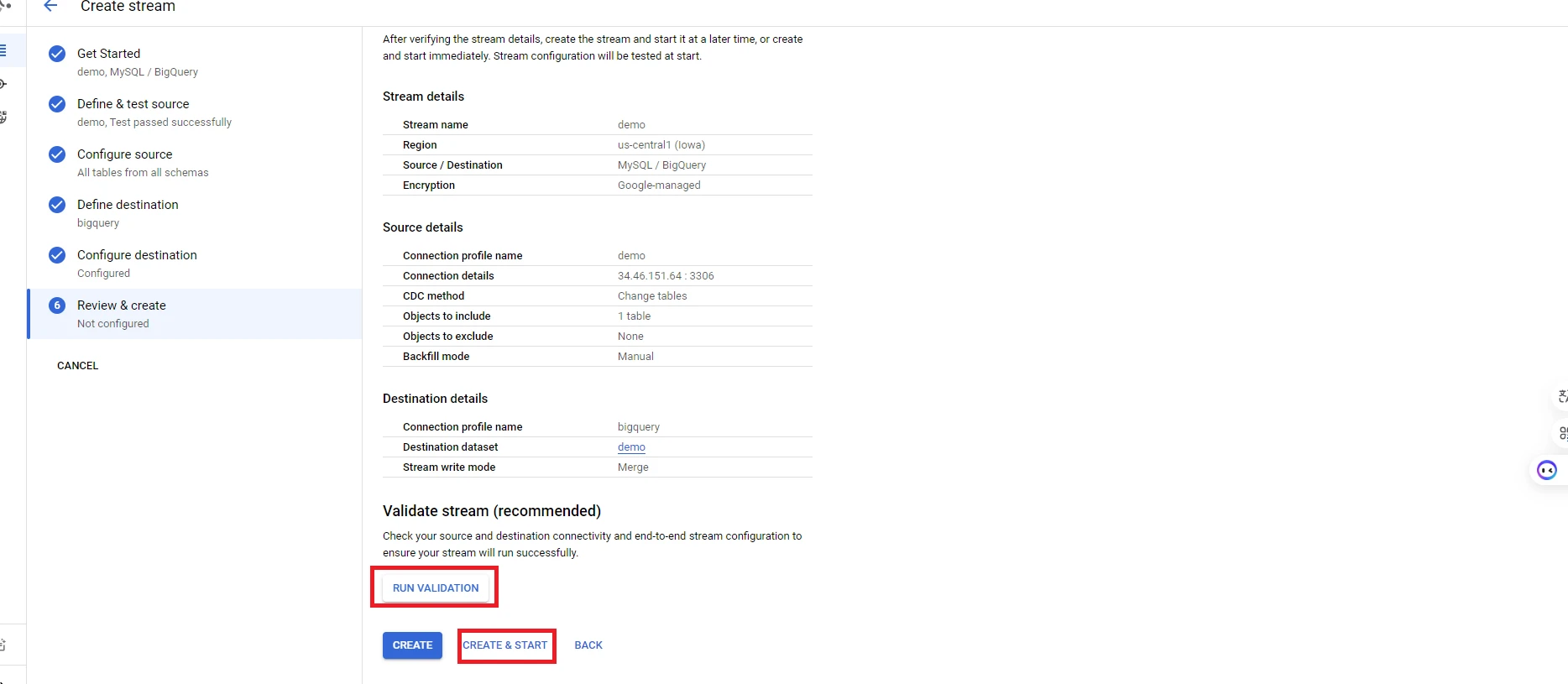
You have completed the setup of Datastream to transfer data from the Database to BigQuery. Next, we will guide you on how to use Scheduled Queries to generate periodic reports.
1. Go to the BigQuery page and add a Report table
2. Turn on the Query tab to write the query for generating reports
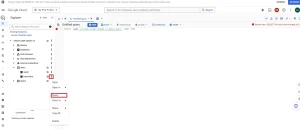
3. After completing, click ‘SCHEDULE’ section to schedule the periodic execution of the query
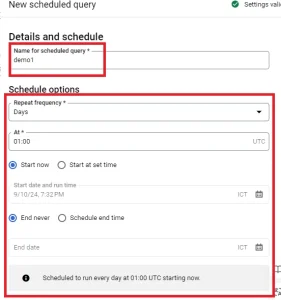
4. Fill the information in the ‘New scheduled query’ table:
– Name for scheduled query: Enter scheduled query name
– Schedule options: Set the frequency for executing the query: hourly, daily, weekly, etc., along with other related options
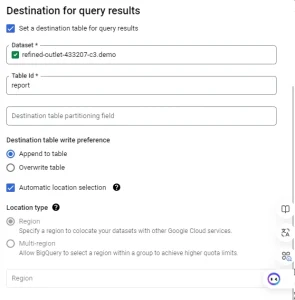
– Destination for query results:
+ Dataset: Select the Dataset where the aggregated data will be inserted
+ TableId: Choose the table that will store the aggregated data
+ Destination table write preference:
- Append to table: New data will be inserted into the table
- Overwrite table: New data will overwrite the existing table
– Service account: Select the account that will execute the scheduled query
– Notification option: Send notifications to the account if the scheduled query fails to execute
You have now completed the setup of Scheduled Query to generate periodic reports